Tuyên ngôn Dimensional modeling
Dimensional modeling (DM) là tên của một kỹ thuật thiết kế logic thường được sử dụng cho các kho dữ liệu. Nó khác và trái ngược với entity-relation modeling (ER). Bài viết này chỉ ra nhiều điểm khác biệt giữa hai kỹ thuật và vẽ một đường thẳng trên cát. Dimensional modeling là kỹ thuật khả thi duy nhất cho cơ sở dữ liệu được thiết kế để hỗ trợ các truy vấn của người dùng cuối trong kho dữ liệu. ER rất hữu ích cho việc thu thập giao dịch và các giai đoạn quản trị dữ liệu khi xây dựng một kho dữ liệu, nhưng nó nên được tránh để phân phối cho người dùng cuối.
entity-relation modeling là gì?
ER là một kỹ thuật thiết kế logic tìm cách loại bỏ phần dư thừa trong dữ liệu. Hãy tưởng tượng rằng chúng ta có một doanh nghiệp nhận đơn đặt hàng và bán sản phẩm cho khách hàng. Trong những ngày đầu của máy tính (rất lâu trước cơ sở dữ liệu quan hệ) khi chúng ta lần đầu tiên chuyển dữ liệu này sang máy tính, chúng ta có thể nắm bắt thứ tự giấy ban đầu như một bản ghi béo duy nhất với nhiều trường. Một bản ghi như vậy có thể dễ dàng có 1.000 byte được phân phối trên 50 trường. Các mục hàng của đơn đặt hàng có thể được biểu diễn dưới dạng một nhóm trường lặp lại được nhúng trong bản ghi chính. Có dữ liệu này trên máy tính rất hữu ích, nhưng chúng tôi nhanh chóng học được một số bài học cơ bản về lưu trữ và thao tác với dữ liệu. Một trong những bài học mà chúng tôi rút ra là dữ liệu ở dạng này rất khó để giữ nhất quán vì mỗi bản ghi đều đứng riêng. Khách hàng’ tên và địa chỉ của s xuất hiện nhiều lần, vì dữ liệu này được lặp lại bất cứ khi nào một đơn hàng mới được thực hiện. Dữ liệu không nhất quán tràn lan vì tất cả các trường hợp của địa chỉ khách hàng đều độc lập và việc cập nhật địa chỉ của khách hàng là một giao dịch lộn xộn.
Ngay cả trong những ngày đầu tiên, chúng tôi đã học cách tách dữ liệu thừa thành các bảng riêng biệt, chẳng hạn như tổng thể về khách hàng và tổng thể về sản phẩm – nhưng chúng tôi đã phải trả giá. Hệ thống phần mềm của chúng tôi để truy xuất và xử lý dữ liệu trở nên phức tạp và không hiệu quả vì chúng đòi hỏi sự chú ý cẩn thận đến các thuật toán xử lý để liên kết các tập hợp bảng này với nhau. Chúng tôi cần một hệ thống cơ sở dữ liệu rất tốt trong việc liên kết các bảng. Điều này đã mở đường cho cuộc cách mạng cơ sở dữ liệu quan hệ, nơi cơ sở dữ liệu được dành riêng cho nhiệm vụ này.
Cuộc cách mạng cơ sở dữ liệu quan hệ đã nở rộ vào giữa những năm 1980. Hầu hết chúng ta đã học được cơ sở dữ liệu quan hệ là gì khi đọc cuốn sách hay của Chris Date về chủ đề này, Giới thiệu về Cơ sở dữ liệu quan hệ (Addison-Wesley), được xuất bản lần đầu vào đầu những năm 1980. Khi chúng tôi duyệt qua cuốn sách của Chris, chúng tôi đã tìm hiểu tất cả các ví dụ về cơ sở dữ liệu Bộ phận, Nhà cung cấp và Thành phố của anh ấy. Hầu hết chúng tôi đều không đặt ra câu hỏi liệu dữ liệu đã hoàn toàn “chuẩn hóa” hay bất kỳ bảng nào trong số các bảng có thể được “phủ tuyết” hay không và Chris đã không phát triển các chủ đề này. Theo ý kiến của tôi, Chris đang cố gắng giải thích các khái niệm cơ bản hơn về cách nghĩ về các bảng được nối với nhau một cách quan hệ.
Kỹ thuật mô hình ER là một kỹ thuật được sử dụng để làm sáng tỏ các mối quan hệ vi mô giữa các phần tử dữ liệu. Hình thức nghệ thuật cao nhất của mô hình ER là loại bỏ tất cả phần dư thừa trong dữ liệu. Điều này vô cùng có lợi cho việc xử lý giao dịch vì các giao dịch được thực hiện rất đơn giản và mang tính xác định. Giao dịch cập nhật địa chỉ của khách hàng có thể chuyển sang một lần tra cứu bản ghi trong bảng chính địa chỉ khách hàng. Việc tra cứu này được kiểm soát bởi khóa địa chỉ khách hàng, khóa này xác định tính duy nhất của bản ghi địa chỉ khách hàng và cho phép tra cứu được lập chỉ mục cực kỳ nhanh chóng. Có thể nói rằng sự thành công của việc xử lý giao dịch trong cơ sở dữ liệu quan hệ chủ yếu là do tính kỷ luật của mô hình ER.
Tuy nhiên, với lòng nhiệt thành để làm cho việc xử lý giao dịch hiệu quả, chúng tôi đã đánh mất mục tiêu ban đầu, quan trọng nhất của mình. Chúng tôi đã tạo cơ sở dữ liệu không thể truy vấn! Ngay cả ví dụ lấy thứ tự đơn giản của chúng tôi cũng tạo ra một cơ sở dữ liệu gồm hàng chục bảng được liên kết với nhau bằng một mạng nhện liên kết gây hoang mang. ( Xem Hình 1 , trang 60.) Tất cả chúng ta đều quen thuộc với biểu đồ lớn trên tường của phòng thiết kế cơ sở dữ liệu IS. Mô hình ER cho doanh nghiệp có hàng trăm thực thể logic! Các hệ thống cao cấp như SAP có hàng nghìn thực thể. Mỗi thực thể này thường biến thành một bảng vật lý khi cơ sở dữ liệu được triển khai. Tình huống này không chỉ là một sự khó chịu, nó còn là một sự phô trương:
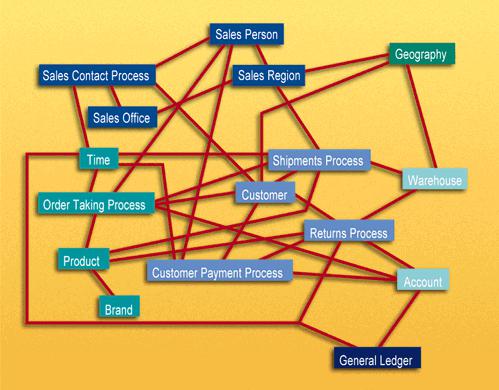
- Người dùng cuối không thể hiểu hoặc nhớ một mô hình ER. Người dùng cuối không thể điều hướng mô hình ER. Không có giao diện người dùng đồ họa (GUI) lấy mô hình ER chung và làm cho người dùng cuối có thể sử dụng được.
- Phần mềm không thể truy vấn hữu ích một mô hình ER chung. Các trình tối ưu hóa dựa trên chi phí cố gắng thực hiện điều này nổi tiếng là đưa ra các lựa chọn sai, với hậu quả tai hại cho hiệu suất.
- Việc sử dụng kỹ thuật mô hình ER đánh bại sức hấp dẫn cơ bản của việc lưu trữ dữ liệu, cụ thể là truy xuất dữ liệu trực quan và hiệu suất cao.
Kể từ khi bắt đầu cuộc cách mạng cơ sở dữ liệu quan hệ, các cửa hàng IS đã nhận thấy vấn đề này. Nhiều người trong số họ đã cố gắng cung cấp dữ liệu cho người dùng cuối đã nhận ra rằng việc trình bày các lược đồ vô cùng phức tạp này cho người dùng cuối là không thể, và nhiều cửa hàng IS đã lùi lại để thử “thiết kế đơn giản hơn”. Tôi thấy thật ấn tượng khi những thiết kế “đơn giản hơn” này trông rất giống nhau! Hầu như tất cả các thiết kế đơn giản hơn này có thể được coi là “chiều”. Theo một cách tự nhiên, gần như vô thức, hàng trăm nhà thiết kế IS đã quay trở lại gốc rễ của mô hình quan hệ ban đầu vì họ biết rằng cơ sở dữ liệu không thể được sử dụng trừ khi nó được đóng gói đơn giản. Có lẽ chính xác khi nói rằng phương pháp tiếp cận theo chiều tự nhiên này không phải do bất kỳ người nào phát minh ra. Đó là một sức mạnh không thể cưỡng lại trong việc thiết kế cơ sở dữ liệu sẽ luôn xuất hiện khi nhà thiết kế đặt sự hiểu biết và hiệu suất làm mục tiêu cao nhất. Bây giờ chúng tôi đã sẵn sàng để xác định cách tiếp cận Dimensional modeling.
Dimensional modeling là gì?
DM là một kỹ thuật thiết kế logic nhằm tìm cách trình bày dữ liệu trong một khuôn khổ tiêu chuẩn, trực quan cho phép truy cập hiệu suất cao. Nó vốn có chiều, và nó tuân thủ kỷ luật sử dụng mô hình quan hệ với một số hạn chế quan trọng. Mọi mô hình chiều đều bao gồm một bảng có khóa nhiều phần, được gọi là bảng dữ kiện và một tập hợp các bảng nhỏ hơn được gọi là bảng kích thước. Mỗi bảng thứ nguyên có một khóa chính gồm một phần tương ứng chính xác với một trong các thành phần của khóa nhiều phần trong bảng dữ kiện. ( Xem Hình 2. ) Cấu trúc “giống sao” đặc trưng này thường được gọi là nối sao. Thuật ngữ nối sao có từ những ngày đầu tiên của cơ sở dữ liệu quan hệ.
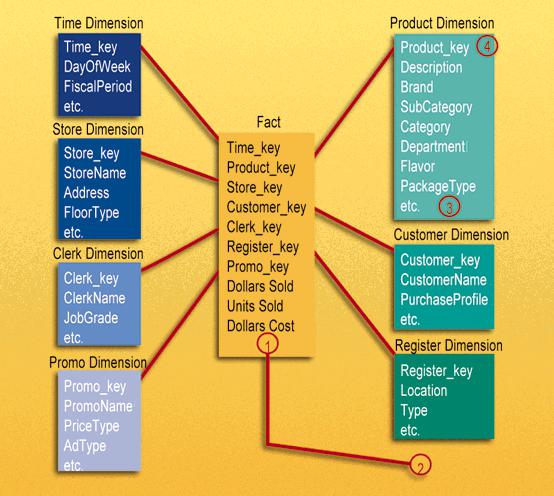
Bảng dữ kiện, bởi vì nó có khóa chính nhiều phần được tạo thành từ hai hoặc nhiều khóa ngoại, luôn thể hiện mối quan hệ nhiều-nhiều. Các bảng dữ kiện hữu ích nhất cũng chứa một hoặc nhiều số đo hoặc “dữ kiện”, xảy ra cho tổ hợp các khóa xác định mỗi bản ghi. Trong Hình 2, các dữ kiện là Đô la đã bán, Đơn vị đã bán và Chi phí Đô la. Các dữ kiện hữu ích nhất trong bảng dữ kiện là số và cộng. Độ nhạy là rất quan trọng vì các ứng dụng kho dữ liệu hầu như không bao giờ truy xuất một bản ghi bảng dữ kiện nào; thay vào đó, họ lấy lại hàng trăm, hàng nghìn hoặc thậm chí hàng triệu bản ghi này cùng một lúc và điều hữu ích duy nhất để làm với rất nhiều bản ghi là thêm chúng vào.
Ngược lại, bảng thứ nguyên thường chứa thông tin văn bản mô tả. Thuộc tính thứ nguyên được sử dụng làm nguồn của hầu hết các ràng buộc thú vị trong các truy vấn kho dữ liệu và chúng hầu như luôn là nguồn của tiêu đề hàng trong bộ câu trả lời SQL. Trong Hình 2, chúng tôi hạn chế đối với các sản phẩm có hương vị Chanh thông qua thuộc tính Hương vị trong bảng Sản phẩm và các chương trình khuyến mãi trên Radio thông qua thuộc tính Loại quảng cáo trong bảng Khuyến mại. Rõ ràng là sức mạnh của cơ sở dữ liệu trong Hình 2 tỷ lệ thuận với chất lượng và độ sâu của các bảng kích thước.
Điểm hấp dẫn của thiết kế cơ sở dữ liệu trong Hình 2 là nó rất dễ nhận biết đối với người dùng cuối trong doanh nghiệp cụ thể. Tôi đã quan sát hàng trăm trường hợp người dùng cuối đồng ý ngay lập tức rằng đây là “công việc của họ.”
Dimensional modeling so với entity-relation modeling
Rõ ràng, Hình 1 và Hình 2 trông khá khác nhau. Nhiều nhà thiết kế phản ứng với điều này bằng cách nói, “Phải có ít thông tin hơn trong liên kết ngôi sao” hoặc “Liên kết sao chỉ được sử dụng cho các bản tóm tắt cấp cao.” Cả hai câu này đều sai.
Chìa khóa để hiểu mối quan hệ giữa DM và ER là một sơ đồ ER đơn lẻ được chia thành nhiều sơ đồ DM. Hãy nghĩ về một sơ đồ ER lớn đại diện cho mọi quy trình kinh doanh có thể có trong doanh nghiệp. Sơ đồ ER chính có thể có Cuộc gọi bán hàng, Nhập đơn hàng, Hóa đơn gửi hàng, Thanh toán cho khách hàng và Trả lại sản phẩm, tất cả đều nằm trên cùng một sơ đồ. Theo một cách nào đó, sơ đồ ER tự nó gây ra sự bất lợi bằng cách biểu diễn trên một sơ đồ nhiều quá trình không bao giờ cùng tồn tại trong một tập dữ liệu tại một thời điểm nhất quán duy nhất. Không có gì ngạc nhiên khi biểu đồ ER quá phức tạp. Do đó, bước đầu tiên trong việc chuyển đổi một sơ đồ ER thành một tập hợp các sơ đồ DM là tách sơ đồ ER thành các quy trình nghiệp vụ rời rạc của nó và lập mô hình từng quy trình riêng biệt.
Bước thứ hai là chọn các mối quan hệ nhiều-nhiều đó trong mô hình ER có chứa các dữ kiện không khóa dạng số và cộng và chỉ định chúng dưới dạng bảng dữ kiện. Bước thứ ba là biến tất cả các bảng còn lại thành bảng phẳng với các khóa một phần kết nối trực tiếp với bảng dữ kiện. Các bảng này trở thành bảng kích thước. Trong trường hợp một bảng thứ nguyên kết nối với nhiều bảng dữ kiện, chúng tôi biểu diễn bảng thứ nguyên này trong cả hai lược đồ và chúng tôi gọi các bảng thứ nguyên là “phù hợp” giữa hai mô hình chiều.
Mô hình Dimensional modeling tổng thể thu được của một kho dữ liệu cho một doanh nghiệp lớn sẽ bao gồm khoảng từ 10 đến 25 lược đồ kết hợp sao trông rất giống nhau. Mỗi tham gia sao sẽ có từ bốn đến 12 bảng thứ nguyên. Nếu thiết kế đã được thực hiện đúng, nhiều bảng kích thước này sẽ được chia sẻ từ bảng thực tế sang bảng thực tế. Các ứng dụng đi sâu vào sẽ chỉ đơn giản là thêm nhiều thuộc tính thứ nguyên hơn vào bộ câu trả lời SQL từ trong một phép nối sao duy nhất. Các ứng dụng đi sâu vào sẽ chỉ đơn giản là liên kết các bảng dữ kiện riêng biệt với nhau thông qua các thứ nguyên (được chia sẻ) phù hợp. Mặc dù bộ tổng thể các lược đồ nối sao trong mô hình chiều doanh nghiệp rất phức tạp, việc xử lý truy vấn rất dễ đoán vì ở cấp thấp nhất, tôi khuyên rằng mỗi bảng dữ kiện nên được truy vấn độc lập.
Điểm mạnh của Dimensional modeling
Mô hình chiều có một số lợi thế kho dữ liệu quan trọng mà mô hình ER thiếu. Đầu tiên, mô hình chiều là một khung tiêu chuẩn, có thể dự đoán được. Người viết báo cáo, công cụ truy vấn và giao diện người dùng đều có thể đưa ra các giả định mạnh mẽ về mô hình chiều để làm cho giao diện người dùng dễ hiểu hơn và để xử lý hiệu quả hơn. Ví dụ: vì gần như tất cả các ràng buộc do người dùng cuối thiết lập đều đến từ các bảng thứ nguyên, công cụ dành cho người dùng cuối có thể cung cấp khả năng “duyệt” hiệu suất cao trên các thuộc tính trong một thứ nguyên thông qua việc sử dụng chỉ mục vector bit. Siêu dữ liệu có thể sử dụng số lượng giá trị đã biết trong một thứ nguyên để hướng dẫn hành vi của giao diện người dùng. Khung có thể dự đoán mang lại lợi thế to lớn trong quá trình xử lý. Thay vì sử dụng trình tối ưu hóa dựa trên chi phí, một công cụ cơ sở dữ liệu có thể đưa ra các giả định rất mạnh về việc giới hạn các bảng thứ nguyên trước tiên và sau đó “tấn công” bảng dữ kiện cùng một lúc với tích Descartes của các khóa bảng thứ nguyên đó thỏa mãn các ràng buộc của người dùng. Thật đáng ngạc nhiên, bằng cách sử dụng cách tiếp cận này, có thể đánh giá các phép nối n-chiều tùy ý vào một bảng dữ kiện trong một lần chuyển qua chỉ mục của bảng dữ kiện. Chúng ta đã quá quen với việc coi các phép nối n-way là “khó” đến nỗi cả một thế hệ DBA không nhận ra rằng vấn đề nối n-way về mặt hình thức tương đương với một phép hợp nhất sắp xếp. Có thật không. bằng cách sử dụng phương pháp này, có thể đánh giá các phép nối n chiều tùy ý vào một bảng dữ kiện trong một lần chuyển qua chỉ mục của bảng dữ kiện. Chúng ta đã quá quen với việc coi các phép nối n-way là “khó” đến nỗi cả một thế hệ DBA không nhận ra rằng vấn đề nối n-way về mặt hình thức tương đương với một phép hợp nhất sắp xếp. Có thật không. bằng cách sử dụng phương pháp này, có thể đánh giá các phép nối n chiều tùy ý vào một bảng dữ kiện trong một lần chuyển qua chỉ mục của bảng dữ kiện. Chúng ta đã quá quen với việc coi các phép nối n-way là “khó” đến nỗi cả một thế hệ DBA không nhận ra rằng vấn đề nối n-way về mặt hình thức tương đương với một phép hợp nhất sắp xếp. Có thật không.
Điểm mạnh thứ hai của mô hình chiều là khung có thể dự đoán được của lược đồ nối sao chịu được những thay đổi không mong muốn trong hành vi của người dùng. Mọi thứ nguyên đều tương đương. Tất cả các kích thước có thể được coi là các điểm nhập đối xứng bằng nhau vào bảng dữ kiện. Thiết kế logic có thể được thực hiện độc lập với các mẫu truy vấn dự kiến. Các giao diện người dùng là đối xứng, các chiến lược truy vấn là đối xứng và SQL được tạo ra dựa trên mô hình chiều là đối xứng.
Điểm mạnh thứ ba của mô hình chiều là nó có thể mở rộng một cách duyên dáng để chứa các phần tử dữ liệu mới bất ngờ và các quyết định thiết kế mới. Khi chúng tôi nói có thể mở rộng một cách duyên dáng, chúng tôi muốn nói đến một số điều. Đầu tiên, tất cả các bảng hiện có (cả dữ liệu và thứ nguyên) có thể được thay đổi tại chỗ bằng cách chỉ cần thêm các hàng dữ liệu mới trong bảng hoặc có thể thay đổi bảng tại chỗ bằng lệnh SQL thay đổi bảng. Dữ liệu không cần phải được tải lại. Khả năng mở rộng hữu ích cũng có nghĩa là không có công cụ truy vấn hoặc công cụ báo cáo nào cần được lập trình lại để phù hợp với thay đổi. Và cuối cùng, khả năng mở rộng duyên dáng có nghĩa là tất cả các ứng dụng cũ tiếp tục chạy mà không mang lại kết quả khác. Trong hình 2, Tôi đã gắn nhãn lược đồ với các số từ 1 đến 4 cho biết nơi bạn có thể, tương ứng, thực hiện các thay đổi duyên dáng sau đối với thiết kế sau khi kho dữ liệu được thiết lập và chạy bằng cách:
- Thêm dữ kiện không lường trước mới (nghĩa là các trường số cộng mới trong bảng dữ kiện), miễn là chúng phù hợp với đặc điểm cơ bản của bảng dữ kiện hiện có
- Thêm thứ nguyên hoàn toàn mới, miễn là có một giá trị duy nhất của thứ nguyên đó được xác định cho mỗi hồ sơ dữ kiện hiện có
- Thêm các thuộc tính chiều mới không lường trước được
- Phá vỡ các bản ghi thứ nguyên hiện có xuống mức chi tiết thấp hơn từ một thời điểm nhất định trở đi.
Điểm mạnh thứ tư của mô hình chiều là có một loạt các phương pháp tiếp cận tiêu chuẩn để xử lý các tình huống mô hình phổ biến trong thế giới kinh doanh. Mỗi tình huống này có một tập hợp các lựa chọn thay thế được hiểu rõ có thể được lập trình cụ thể trong trình viết báo cáo, công cụ truy vấn và các giao diện người dùng khác. Các tình huống mô hình hóa này bao gồm:
- Thứ nguyên thay đổi chậm, trong đó thứ nguyên “không đổi” như Sản phẩm hoặc Khách hàng thực sự phát triển chậm và không đồng bộ. Mô hình thứ nguyên cung cấp các kỹ thuật cụ thể để xử lý các kích thước thay đổi chậm, tùy thuộc vào môi trường kinh doanh. Xem bài báo DBMS của tôi vào tháng 4 năm 1996 về các kích thước thay đổi từ từ.
- Các sản phẩm không đồng nhất, trong đó một doanh nghiệp như ngân hàng cần theo dõi một số ngành kinh doanh khác nhau cùng nhau trong một tập hợp các thuộc tính và dữ kiện chung duy nhất, nhưng đồng thời nó cần phải mô tả và đo lường các ngành kinh doanh riêng lẻ theo một phong cách riêng biệt cách sử dụng các biện pháp không tương thích.
- Cơ sở dữ liệu trả trước, trong đó các giao dịch của một doanh nghiệp không phải là phần nhỏ của doanh thu, nhưng doanh nghiệp cần phải xem xét các giao dịch riêng lẻ cũng như báo cáo doanh thu một cách thường xuyên. Về phần này và phần trước, hãy xem bài báo DBMS của tôi vào tháng 12 năm 1995, nghiên cứu điển hình về công ty bảo hiểm.
- Cơ sở dữ liệu xử lý sự kiện, trong đó bảng dữ kiện thường hóa ra là “phi dữ kiện”. Xem bài báo DBMS của tôi vào tháng 9 năm 1996 trên các bảng dữ kiện phi thực tế.
Điểm mạnh cuối cùng của mô hình thứ nguyên là sự gia tăng của các tiện ích quản trị và quy trình phần mềm quản lý và sử dụng tổng hợp. Nhớ lại rằng tổng hợp là các bản ghi tóm tắt dư thừa về mặt logic với dữ liệu cơ sở đã có trong kho dữ liệu, nhưng chúng được sử dụng để nâng cao hiệu suất truy vấn. Cần có một chiến lược tổng hợp toàn diện trong mọi triển khai kho dữ liệu quy mô vừa và lớn. Nói cách khác, nếu bạn không có tổng hợp, thì bạn có khả năng lãng phí hàng triệu đô la cho việc nâng cấp phần cứng để giải quyết các vấn đề về hiệu suất mà có thể được giải quyết bằng cách tổng hợp.
Tất cả các gói phần mềm quản lý tổng hợp và các tiện ích điều hướng tổng hợp phụ thuộc vào một cấu trúc duy nhất rất cụ thể của bảng dữ liệu và bảng kích thước hoàn toàn phụ thuộc vào mô hình chiều. Nếu bạn không tuân thủ cách tiếp cận theo chiều, bạn không thể hưởng lợi từ những công cụ này. Vui lòng xem các bài viết về DBMS của tôi về điều hướng tổng hợp và các sản phẩm khác nhau phục vụ điều hướng tổng hợp trong các số tháng 9 năm 1995 và tháng 8 năm 1996.
Huyền thoại về Dimensional modeling
Một số huyền thoại nổi xung quanh mô hình chiều đáng được giải quyết. Quan niệm số một là “Việc triển khai mô hình dữ liệu chiều sẽ dẫn đến các hệ thống hỗ trợ ra quyết định của bếp nấu ăn.” Lầm tưởng này đôi khi đổ lỗi cho việc không chuẩn hóa chỉ hỗ trợ các ứng dụng cụ thể do đó không thể thay đổi được. Huyền thoại này là một cách giải thích thiển cận về mô hình chiều đã xoay sở để đưa ra thông điệp ngược lại một cách chính xác! Đầu tiên, chúng tôi lập luận rằng mọi mô hình ER đều có một tập hợp các mô hình Dimensional modeling tương đương chứa cùng một thông tin. Thứ hai, chúng tôi đã chỉ ra rằng ngay cả khi có sự thay đổi của tổ chức và sự thích ứng của người dùng cuối, mô hình chiều vẫn mở rộng một cách duyên dáng mà không thay đổi hình thức của nó. Trên thực tế, nó là mô hình ER đánh bại các nhà thiết kế ứng dụng và người dùng cuối!
Theo tôi, một nguồn gốc của câu chuyện hoang đường này là nhà thiết kế đang vật lộn với các bảng dữ kiện đã được tổng hợp quá sớm. Ví dụ: thiết kế trong Hình 2 được thể hiện ở cấp mục hàng bán vé riêng lẻ. Đây là điểm khởi đầu chính xác cho cơ sở dữ liệu bán lẻ này vì đây là mức dữ liệu thấp nhất có thể. Không có bất kỳ sự cố nào khác về giao dịch bán hàng. Nếu nhà thiết kế bắt đầu với một bảng dữ kiện đã được tổng hợp đến tổng doanh số hàng tuần theo cửa hàng, thì sẽ có đủ loại vấn đề khi thêm thứ nguyên mới, thuộc tính mới và dữ kiện mới. Tuy nhiên, đây không phải là vấn đề với kỹ thuật thiết kế, đây là vấn đề với việc cơ sở dữ liệu được tổng hợp quá sớm.
Quan niệm thứ hai là “Không ai hiểu được mô hình chiều.” Huyền thoại này là vô lý. Tôi đã thấy hàng trăm thiết kế chiều tuyệt vời được tạo ra bởi những người mà tôi chưa từng gặp hoặc từng có trong lớp của mình. Cả một thế hệ các nhà thiết kế từ ngành sản xuất và bán lẻ hàng đóng gói đã sử dụng và thiết kế cơ sở dữ liệu chiều trong 15 năm qua. Cá nhân tôi đã học về các mô hình chiều từ các ứng dụng AC Nielsen và IRI hiện có đã được cài đặt và hoạt động ở những nơi như Procter & Gamble và The Clorox Company ngay từ năm 1982.
Ngẫu nhiên, mặc dù bài viết này đã được đúc kết về cơ sở dữ liệu quan hệ, nhưng gần như tất cả các lập luận ủng hộ sức mạnh của mô hình chiều hoàn toàn phù hợp với các cơ sở dữ liệu đa chiều độc quyền như Oracle Express và Arbor Essbase.
Quan niệm thứ ba là “Mô hình thứ nguyên chỉ hoạt động với cơ sở dữ liệu bán lẻ.” Huyền thoại này bắt nguồn từ nguồn gốc lịch sử của mô hình chiều nhưng không phải trong thực tế ngày nay của nó. Mô hình chiều đã được áp dụng cho nhiều lĩnh vực kinh doanh khác nhau bao gồm ngân hàng bán lẻ, ngân hàng thương mại, bảo hiểm tài sản và thương vong, bảo hiểm sức khỏe, bảo hiểm nhân thọ, phân tích khách hàng môi giới, hoạt động của công ty điện thoại, quảng cáo trên báo, bán nhiên liệu của công ty dầu, chi tiêu của cơ quan chính phủ và sản xuất các lô hàng.
Quan niệm thứ 4 là “Trượt tuyết là một giải pháp thay thế cho mô hình chiều.” Snowflaking là việc loại bỏ các thuộc tính văn bản có số lượng thấp khỏi bảng thứ nguyên và vị trí của các thuộc tính này trong bảng thứ nguyên “phụ”. Ví dụ: một danh mục sản phẩm có thể được xử lý theo cách này và bị xóa khỏi bảng thứ nguyên sản phẩm cấp thấp. Tôi tin rằng phương pháp này ảnh hưởng đến hiệu suất duyệt thuộc tính chéo và có thể ảnh hưởng đến tính dễ đọc của cơ sở dữ liệu, nhưng tôi biết rằng một số nhà thiết kế tin rằng đây là một cách tiếp cận tốt. Snowflaking chắc chắn không mâu thuẫn với mô hình chiều. Tôi coi việc trượt tuyết như một phần tô điểm cho sự sạch sẽ của mô hình chiều cơ bản. Tôi nghĩ rằng một nhà thiết kế có thể đánh bông tuyết với lương tâm rõ ràng nếu kỹ thuật này cải thiện khả năng hiểu của người dùng và cải thiện hiệu suất tổng thể. Lập luận rằng việc trượt tuyết giúp duy trì bảng thứ nguyên là rất khó. Các vấn đề bảo trì thực sự được tận dụng bởi các nguyên tắc giống như ER, nhưng tất cả điều này xảy ra trong kho lưu trữ dữ liệu hoạt động, trước khi dữ liệu được tải vào lược đồ chiều.
Câu chuyện hoang đường cuối cùng là “Mô hình hóa không gian chỉ hoạt động đối với một số loại dữ liệu đơn chủ đề.” Huyền thoại này là một nỗ lực để loại bỏ mô hình chiều của những cá nhân không hiểu sức mạnh cơ bản và khả năng ứng dụng của nó. Mô hình hóa không gian là kỹ thuật thích hợp cho thiết kế tổng thể của một kho dữ liệu cấp doanh nghiệp hoàn chỉnh. Một thiết kế chiều như vậy bao gồm các họ mô hình chiều, trong đó mỗi họ mô tả một quy trình kinh doanh. Các gia đình được liên kết với nhau một cách hiệu quả bằng cách nhấn mạnh vào việc sử dụng các kích thước phù hợp.
Trong phòng thủ của Dimensional modeling
Bây giờ là lúc để cởi găng tay. Tôi tin chắc rằng mô hình hóa chiều là kỹ thuật khả thi duy nhất để thiết kế cơ sở dữ liệu phân phối người dùng cuối. Mô hình ER đánh bại phân phối của người dùng cuối và không được sử dụng cho mục đích này.
Mô hình ER không thực sự mô hình hóa một doanh nghiệp; đúng hơn, nó mô hình hóa các mối quan hệ vi mô giữa các phần tử dữ liệu. Mô hình ER không có “quy tắc kinh doanh”, nó có “quy tắc dữ liệu”. Rất ít nếu bất kỳ yêu cầu thiết kế toàn cầu nào trong phương pháp lập mô hình ER nói lên tính hoàn chỉnh của thiết kế tổng thể. Ví dụ: công cụ ER CASE của bạn có cố gắng cho bạn biết liệu tất cả các đường dẫn tham gia có thể có được biểu diễn hay không và có bao nhiêu đường dẫn? Bạn thậm chí còn quan tâm đến những vấn đề như vậy trong một thiết kế ER? ER có gì để nói về các tình huống mô hình kinh doanh tiêu chuẩn chẳng hạn như kích thước thay đổi chậm?
Mô hình ER có cấu trúc rất khác nhau. Nói trước cho tôi biết cách tối ưu hóa truy vấn hàng trăm bảng có liên quan với nhau trong một mô hình ER lớn. Ngược lại, ngay cả một bộ lớn các mô hình chiều cũng có một chiến lược xác định tổng thể để đánh giá mọi truy vấn có thể có, ngay cả những truy vấn vượt qua nhiều bảng dữ kiện. (Gợi ý: Bạn kiểm soát hiệu suất bằng cách truy vấn từng bảng dữ kiện riêng biệt. Nếu bạn thực sự tin rằng bạn có thể kết hợp nhiều bảng dữ kiện với nhau trong một truy vấn duy nhất và tin tưởng trình tối ưu hóa dựa trên chi phí để quyết định kế hoạch thực hiện, thì bạn đã không triển khai kho dữ liệu cho người dùng cuối thực sự.)
Sự biến đổi hoang dã của cấu trúc của các mô hình ER có nghĩa là mỗi kho dữ liệu cần SQL tùy chỉnh, viết tay và điều chỉnh. Điều đó cũng có nghĩa là mỗi giản đồ, một khi nó được điều chỉnh, sẽ rất dễ bị thay đổi thói quen truy vấn của người dùng, bởi vì các lược đồ như vậy là không đối xứng. Ngược lại, trong mô hình chiều, tất cả các thứ nguyên đóng vai trò là các điểm vào bằng nhau trong bảng dữ kiện. Những thay đổi trong thói quen truy vấn của người dùng không làm thay đổi cấu trúc của SQL hoặc các cách tiêu chuẩn để đo lường và kiểm soát hiệu suất.
Các mô hình ER có vị trí của chúng trong kho dữ liệu. Đầu tiên, mô hình ER nên được sử dụng trong tất cả các ứng dụng OLTP kế thừa dựa trên công nghệ quan hệ. Đây là cách tốt nhất để đạt được hiệu suất giao dịch cao nhất và tính toàn vẹn của dữ liệu liên tục cao nhất. Thứ hai, mô hình ER có thể được sử dụng rất thành công trong việc dọn dẹp dữ liệu phòng sau và kết hợp các bước của kho dữ liệu. Đây là ODS, hoặc kho dữ liệu hoạt động.
Tuy nhiên, trước khi dữ liệu được đóng gói thành định dạng có thể truy vấn cuối cùng, nó phải được tải vào mô hình chiều. Mô hình thứ nguyên là kỹ thuật khả thi duy nhất để đạt được cả khả năng hiểu của người dùng và hiệu suất truy vấn cao khi đối mặt với các câu hỏi luôn thay đổi của người dùng.
Tài nguyên mô hình thứ nguyên
- Bộ công cụ Kho Dữ liệu: Các Kỹ thuật Thực hành để Xây dựng Kho Dữ liệu Thứ nguyên , Ralph Kimball, John Wiley, 199
- Giải pháp OLAP: Xây dựng Hệ thống Thông tin Đa chiều , Eric Thomsen, John Wiley, 1997
- Lập kế hoạch và thiết kế kho dữ liệu , Ramon Barquin và Herb Edelstein, chương 10, Prentice Hall PTR, 1996
- Xây dựng kho dữ liệu để hỗ trợ quyết định , Vidette Poe, Prentice Hall, 1995.




{kind=link}
{kind=link}
{kind=link}
{kind=link}